
Using Logistic Regression to Predict Bank Loan Outcomes
Building an interpretable machine learning model to predict loan approval outcomes and identify the key factors driving lending decisions.
Building an interpretable machine learning model to predict loan approval outcomes and identify the key factors driving lending decisions.
Using Logistic Regression, I built a loan approval prediction model, using various stock & engineered features, which achieved an accuracy score of 75.7. My feature analysis revealed that Credit History is the most influential feature in loan approval decisions, while income-related features had surprisingly minimal impact.
Banks often process large amounts of loan applications daily, requiring quick yet accurate decisions that balance risk management with customer service. Understanding which factors truly drive approval decisions helps optimize business processes and aid applicants in submitting stronger applications.
Goal: Can I build a logistic regression model that accurately predicts loan approval outcomes while revealing which applicant characteristics have the most impact to lenders?
I selected Logistic Regression because interpretability was key to solving the business problem. Users not only want to know if their loan is rejected, but why it was rejected. This is something a 'black-box' model like XGBoost or random forest could not provide.
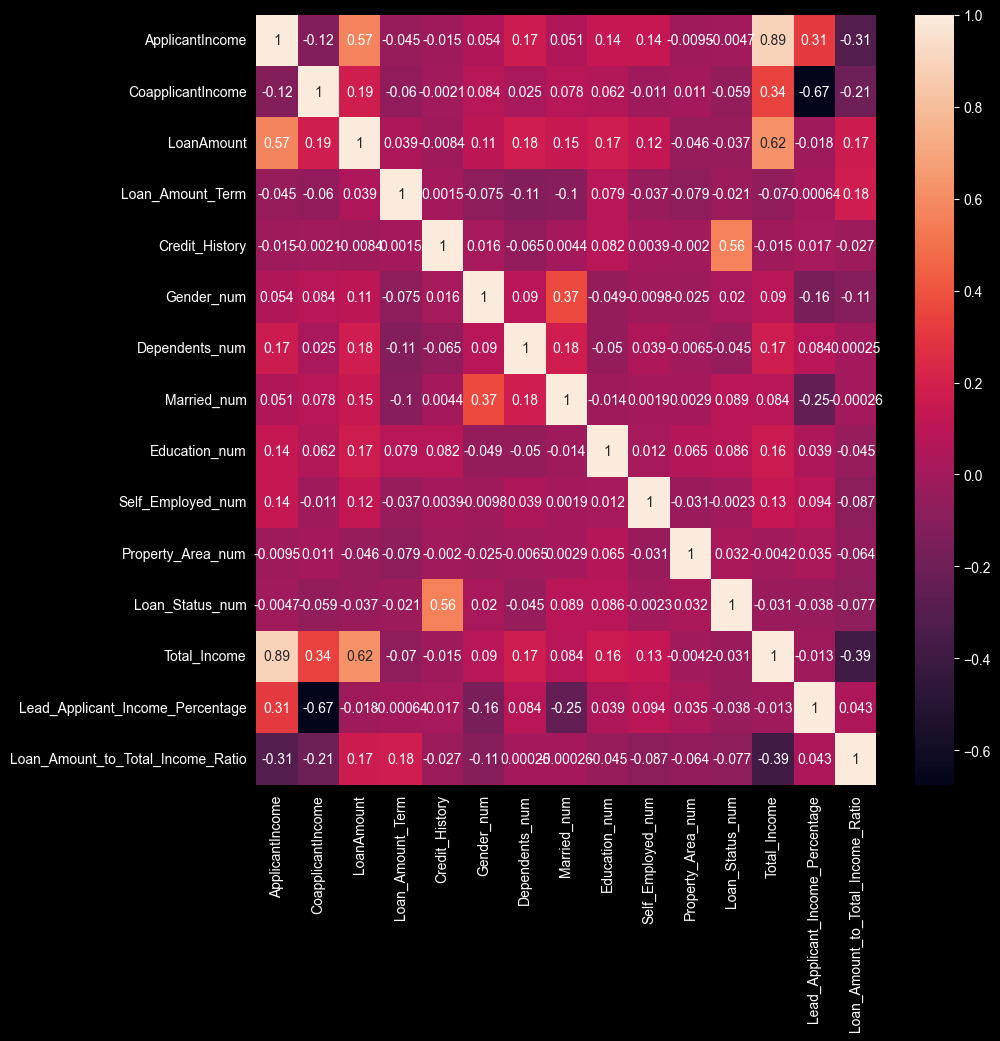
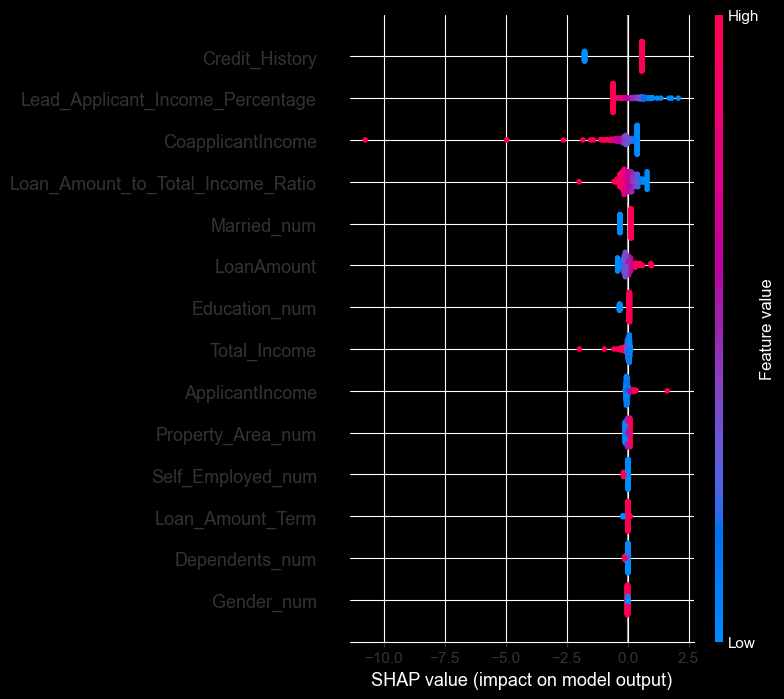
With SHAP values 3-4x larger than any other feature, credit history overwhelmingly determines if the loan is approved or not. Applicants with positive credit history see approval rates dramatically higher than those without.
At the start of this project, one of my pre-conceptions with loans would be the importance of income. However, income-related features showed minimal SHAP importance. The model suggests lenders weight repayment track record far above current earnings.
The model correctly predicted 140 of 185 test cases (28 true negatives, 112 true positives), with particularly strong recall (85%) for approved loans. The 25 false positives indicate conservative tendencies in borderline cases.
Recommendation: Financial institutions should prioritise credit history above all else, as it's the primary driver of loan decisions. Applicants should be clearly informed that building a strong credit history matters more than income when applying for loans. For model deployment, the false positive rate suggests adding a manual review step for predicted approvals where other predictive features are weaker.
This project reinforced the value of explainable AI in high-stakes domains. While a XGBoost or random forest model might have achieved 80%+ accuracy, the SHAP-based insights into lending behavior are more valuable to the business requirements, than those few extra percentage points.
If I revisited this analysis, I would trial different models before settling on Logistic Regression, and explore more feature engineering, as the features I created didn't meaningfully improve the models accuracy. I'd also review the predictions to ensure any biases embedded in credit history data don't disproportionately affect certain demographics, such as gender or age.